Overview
New Project Wizard
Export Wizard
Settings
Purchase and Support
Extraction Pattern
An extraction pattern is a set of data fields that define the positions of the text and images on the web page.
First, you should specify the URL of the page that will be used to create the pattern.
You can type the URL manually or you can click the  button and open the necessary page using the built-in browser.
By default, the URL is equal to the URL of the start page, but you can change it.
If you want to allow scripts in the web browser control turn on the "Enable JavaScript" option.
button and open the necessary page using the built-in browser.
By default, the URL is equal to the URL of the start page, but you can change it.
If you want to allow scripts in the web browser control turn on the "Enable JavaScript" option.
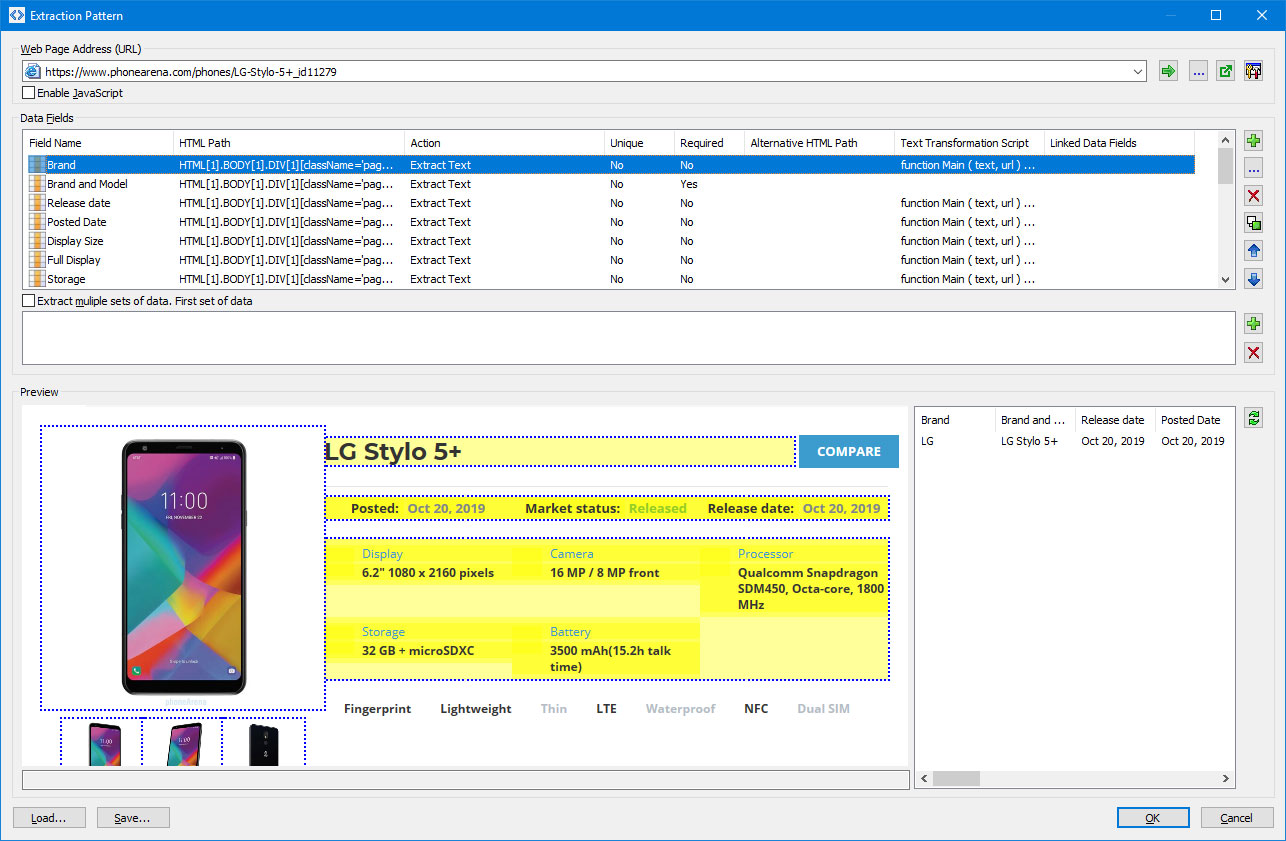
To add new data fields you have to click the  button.
The "Select Data Fields" window appears. Wait till the page is loaded and click every page element you need to extract one by one.
When you click the page element the program highlights it and opens the data field window what allows you to specify the data field parameters.
If the "Use Text Labels" option is enabled, the program tries to find text label associated with the selected element,
and if it exists, adds the transformation script with "sub_string" function to the data field.
You can change the data field paramaters later. To do it, select the corresponding field in the "Data Fields" list and
click the button.
You can also delete, duplicate and move data fields by clicking the corresponding buttons on the right.
button.
The "Select Data Fields" window appears. Wait till the page is loaded and click every page element you need to extract one by one.
When you click the page element the program highlights it and opens the data field window what allows you to specify the data field parameters.
If the "Use Text Labels" option is enabled, the program tries to find text label associated with the selected element,
and if it exists, adds the transformation script with "sub_string" function to the data field.
You can change the data field paramaters later. To do it, select the corresponding field in the "Data Fields" list and
click the button.
You can also delete, duplicate and move data fields by clicking the corresponding buttons on the right.
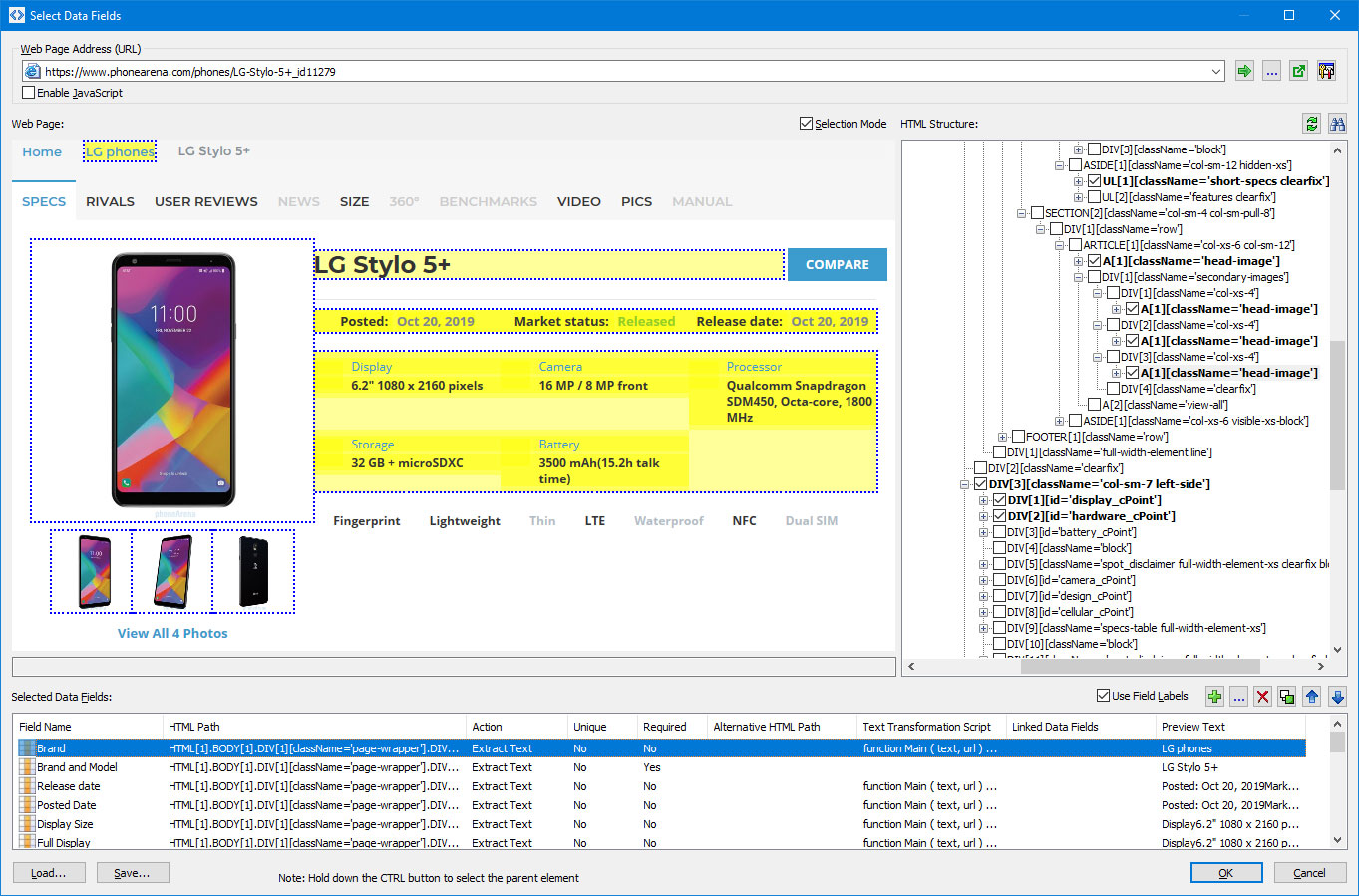
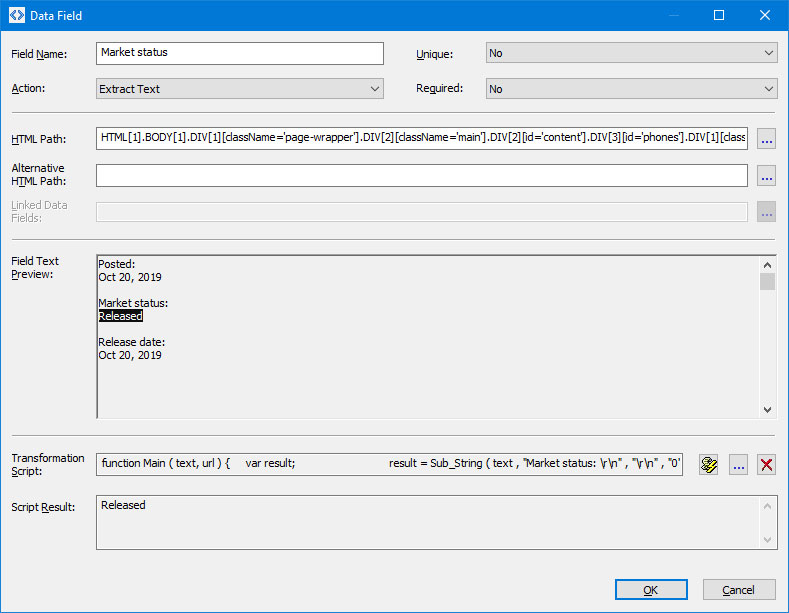
A data field has the following parameters:
- Field Name - field name. You can use any characters except for []."!'?`
-
Action - You can select one of the following actions:
- Extract Text - the program extracts the text of the selected element.
- Extract HTML - the program extracts the HTML text of the selected element from the source code of the page.
- Extract URL - the program extracts the link URL (if the selected element is a link) or the image URL (if the selected element is an image.)
- Save Image/File - the program downloads and saves the selected image to the image folder.
- Save Image/File (dynamic src) - at first the program extracts the HTML text of the selected image, then runs the text transformation script. If the script result will be an URL, then the program downloads and saves the image to the image folder.
- Extract Page URL - the program extracts the current page URL.
- Save Element Screenshot - the program makes a screenshot of the selected element and saves it to the image folder (This action works only if you use "Internet Explorer" browser and turn off the "Use separate thread for parsing" option in the settings window "Tools->Settings->Scraper").
- Click Link and Extract Linked Data - at first the program downloads the selected link url, then extracts data from this page (you have to specify the linked data fields) and combines them with other field data.
- Unique - determines whether this field is unique. If this parameters is set to "Yes", it prevents from saving two records with the same field values.
- Required - determines whether this field is required on the page or in the row. If this parameters is set to "Yes" and this field does not exist on the current page or in the current row, the rest of data is not extracted from this page/row.
-
HTML Path - determines the position of the element on the page. To edit the value, click the button.
-
Alternative HTML Path - determines the alternative position of the element on the page. If the HTML Path does not exist, then the program will use the alternative HTML path.
To edit the value, click the button.
-
Transformation Script - a script to transformate the extracted text. To specify the script, click the button.
- Script Result - the result of processing of the Transformation Script.
- Field Text Preview - the extracted text of the selected element.
If data on the page is presented as a set of rows, you should specify a loop for each row.
The program automatically analyzes the structure of the page and, if it finds a set of rows, it creates a loop for each of these rows.
You can specify or change the loop manually.
To do it, enable the "Extract multiple set of data" option, click the button and
select the parent element that contains all data of the first row and similar elements follow this element in the HTML structure (see fig. 1).
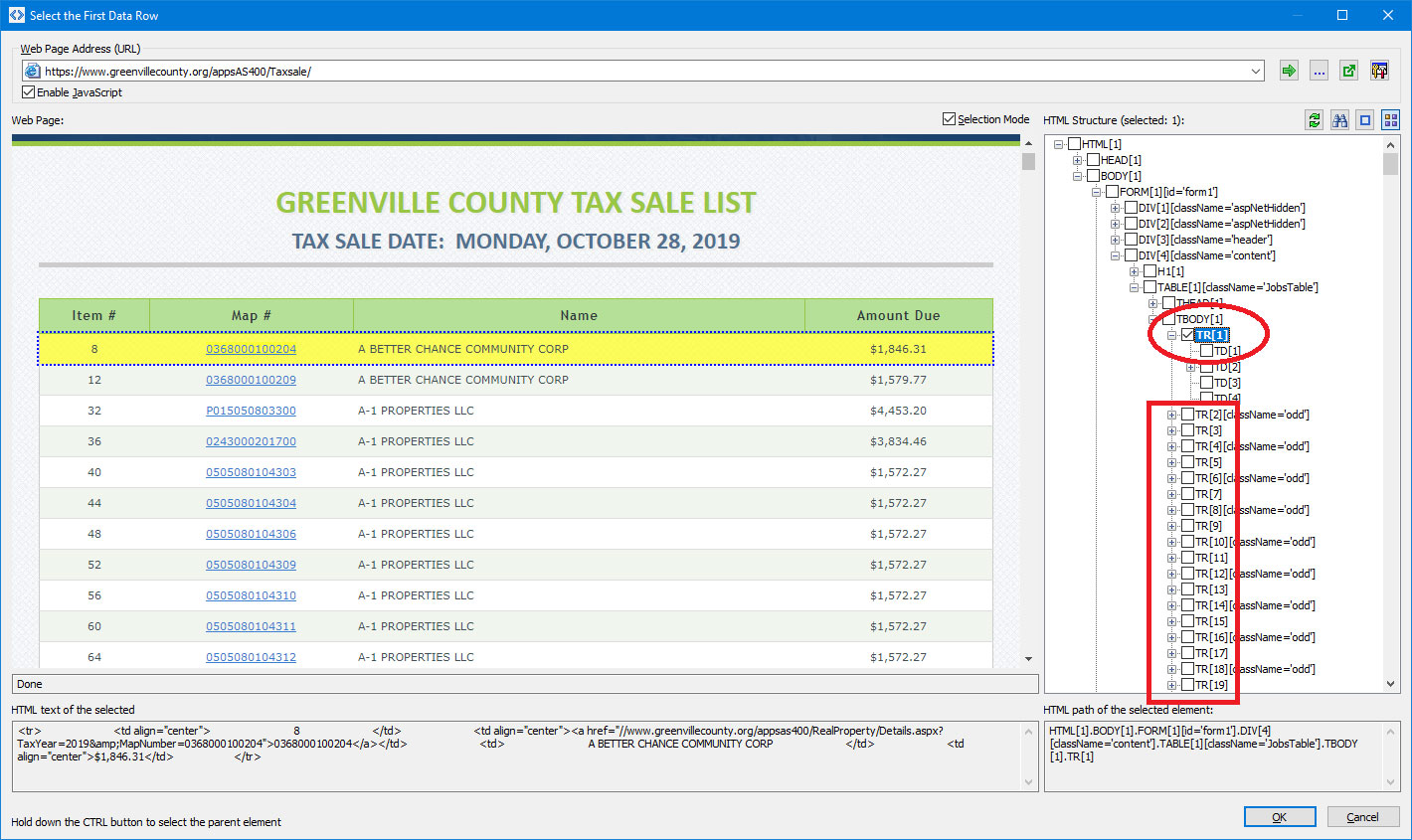
Figure 1.