Overview
New Project Wizard
Export Wizard
Settings
Purchase and Support
Main Window
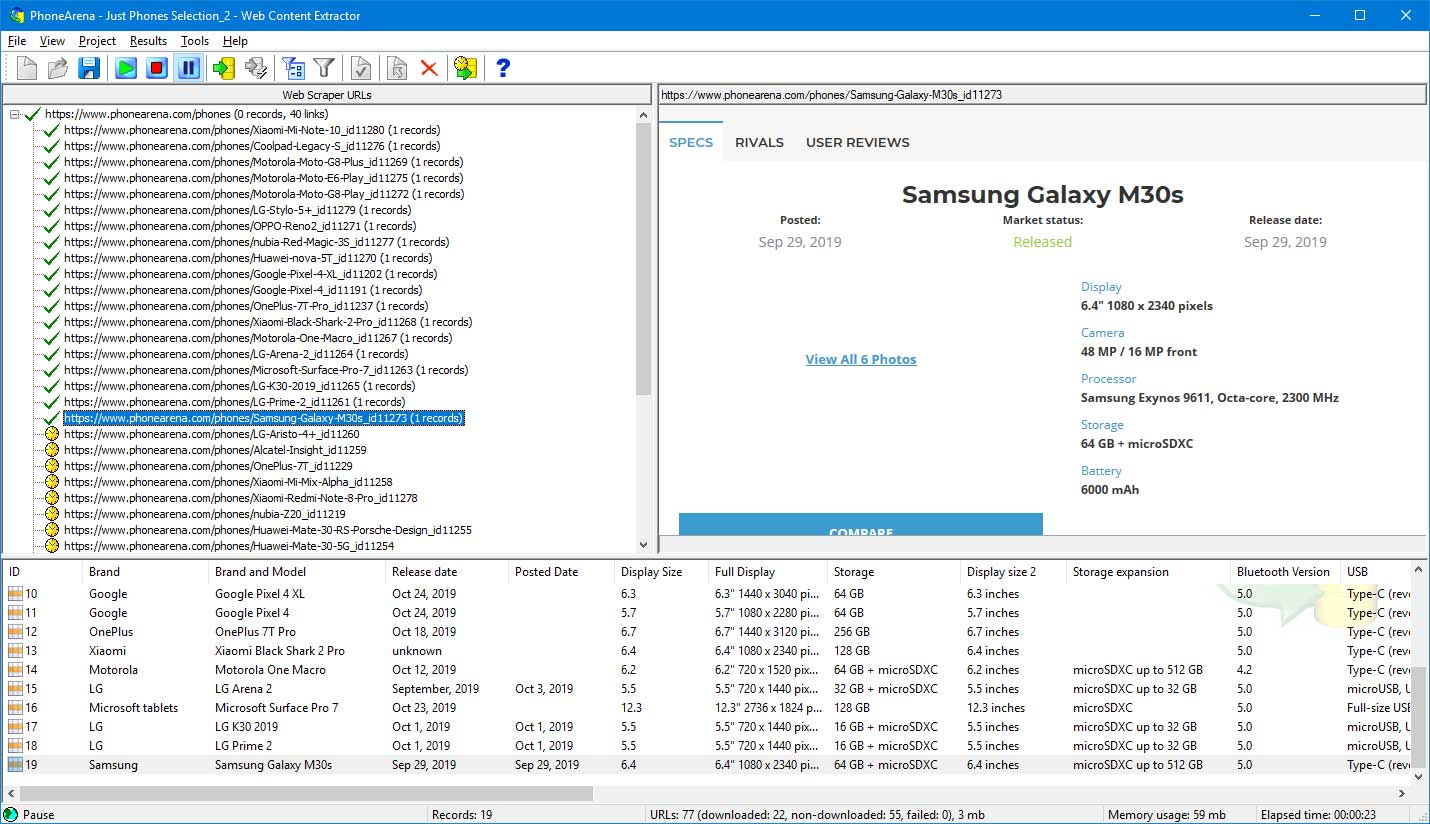
The main window of the program is divided into three parts - Web Scraper URLs (left), Browser Window (right), and Extracted Data Tab (bottom). The program is controlled using the menu and toolbar above while operation progress information is displayed in the status bar under the Extracted Data Tab.
Main Screen
The Menu
All functions of the program are controlled through the menu.
The Toolbar
Some functions of the menu are available through the toolbar
Web Scraper URLs window
Web Scraper URLs window shows a tree structure of the URLs included in the current project.
Browser window
Browser window loads the target web pages.
Extracted Data Tab window
This window shows extracted data in the form of a table that is filled according to extraction pattern you specify before the extraction.
Status bar
The status bar contains five fields. The first field shows operation status. The second one - the number of records listed. The third field shows the number of the total and the downloaded URLs. The fourth one - the memory usage. And the last field shows the elapsed time.