Overview
New Project Wizard
Export Wizard
Settings
Purchase and Support
Settings
You can open the Settings window by clicking "Tools->Settings"or by pressing Alt+F7. This window allows you to change the following settings:
General Tab
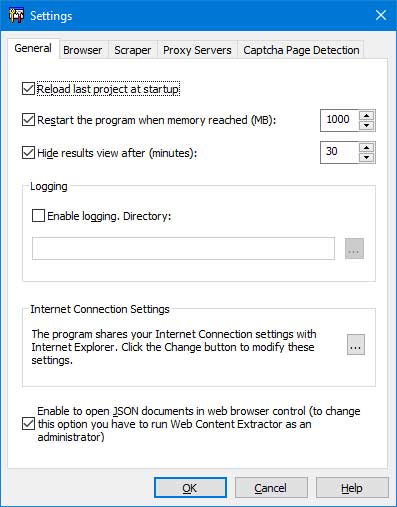
"Reload last project at startup" - if this option is enabled, the program will automatically open the last project when you start the program.
"Restart the program when memory reached" - if this option is enabled and memory reached the limit, then it will be restarted automatically to release the memory.
"Hide the results view after" - if this option is enabled, then the program will hide the results view after x minutes.
"Enable logging" - enable this option if you want to log web scraper events. The logging directory is the directory where the Web Content Extarctor stores log files, the default logging directory is a current directory.
"Internet Connection Settings" - the program uses the Internet connection settings from Internet Explorer. You can change these settings by clicking the "Change"button.
"Enable to open JSON documents in Internet Explorer browser" - to change this option you have to run Web Content Extractor as an administrator.
Browser Tab
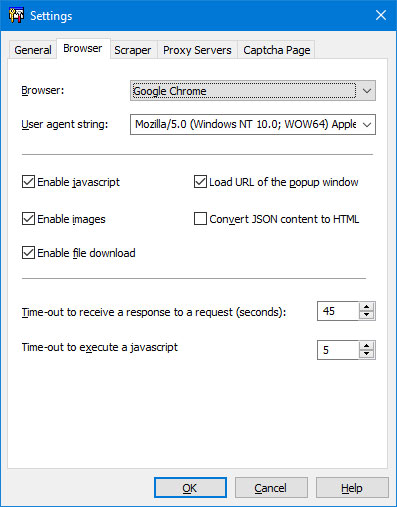
"Browser":
- "Internet Explorer" - the program will use Internet Explorer to download webpages.
- "Google Chrome" - the program will use Google Chrome to download webpages.
"User Agent String " - the string attached to the request header (if you use Google Chrome you need to restart the program to have this change take effect). This is a global setting and applies to all projects.
"Enable javascript" - enable this option if you want to allow scripts in the web browser.
"Enable images" - enable this option if you want to see images in the web browser.
"Enable file download" - This option enables the browser to download files.
"Load URL of the popup window" - if this option is enabled, the program will open popup windows in the main window.
"Convert json content to html" - if this option is enabled, the program will convert json data to html.
"Time-out to receive a response to a request " - the maximum time the program will wait for a response from the server after requesting a page.
"Time-out to execute a javascript" - the maximum time the program will wait to execute a javascript.
Scraper Tab
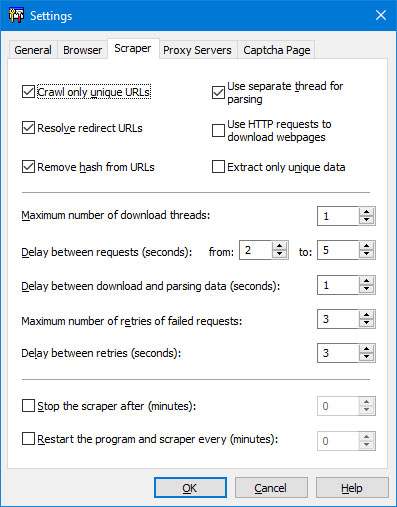
"Crawl only unique URLs" - if this option is enabled, the program will add only new links to the project, i.e. links that are not in the task list yet.
"Resolve redirect URLs" - if this option is enabled, the program will update the URLs of redirected links.
"Remove hash from URLs" - if this option is enabled, the program will remove hash string from the URLs. A hash string is the part of the URL that appears after the '#' sign.
"Disable images in browser" - enable this option if you want to see images in the web browser.
"Use separate thread for parsing" - if this option is enabled, the program will use a separate thread for the parsing process.
"Use HTTP requests to download webpages" - the program will use http requests to download webpages.
"Extract only unique data" - if this option is enabled, the program will add only new data to the project, i.e. data that are not in the database yet.
"Maximum number of download threads" - the number of simultaneous connections to a server.
"Delay between requests" - the delay necessary to prevent the server from being overloaded by multiple requests from the program. We recommend that you set the delay to at least 1-2 seconds.
"Delay between download and parsing data" - the delay that is necessary to execute all scripts on a page.
"Stop the scraper after" - limits the crawling time. Set the number of minutes a project is allowed to run. If this is reached, the program stops the project. If set to zero, no time limit is imposed.
"Restart the program and scraper" - Set the number of minutes to restart the program automatically.
Proxy Servers Tab
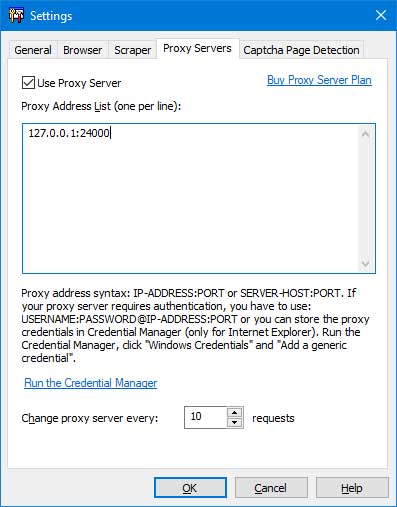
"Use Proxy Server " - if this option is enabled, the program will use proxy server to internet connection. Use the following syntax for the proxy address: <ip_address>:<port> where <ip_address> is the Ip address of the proxy server, and <port> is the port number that is assigned to the proxy server. If your proxy server requires authentication, you have to use: <username>:<password>@<ip_address>:<port>
"Change browser proxy every x requests" - the program will change the browser proxy every x requests.
Captcha Page Tab
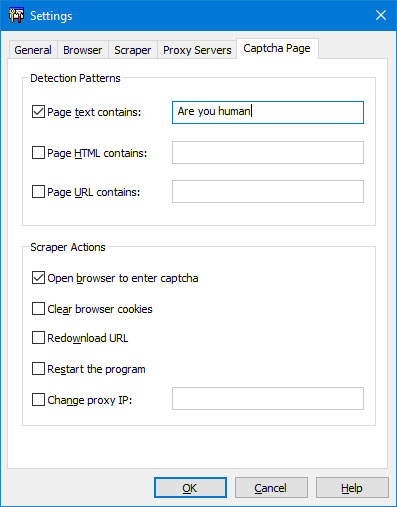
You can specify a page pattern to detect the captcha page. If the program detects the captcha page, it pauses the extraction process and shows the browser window to enable you to enter the captcha text. You can specify three types of page patterns:
- "Page text contains" - the program will scan page text for a pattern.
- "Page HTML contains" - the program will scan page HTML for a pattern.
- "Page URL contains" - the program will scan page URL for a pattern.